This actually exposes how this type of system is just security theater usually.
A shooter can get a badge. Most partitions aren't bulletproof (and probably don't have security film), and a shooter doesn't fear getting a cut on some tempered glass.
The thing that would be effective is 24/7 security monitoring with a building lockdown and reinforced entrances/partitions. Of course, the victims whose badges were disabled during lockdown will sue.
So instead, just install badge readers and say that "something was done".
One uncomfortable, but wise truth is: Actual security is bound to the number of minutes until people with big guns arrive. A lot of other measures just exist to bridge time and limit damages until that happens.
We learned this during a funny situation when a customer sent us the wrong question set for vendors. We were asked to clarify our plans for example for an armed intrusion by an armed, hostile force to seize protected assets from us. After some discussion, we answered the equivalent of "Uh Sir. This is a software company. We would surrender and try to call the cops".
During some laughter from the customer they told us, the only part missing from that answer was the durability rating of our safes and secure storages for assets, of which we had none, because they just had to last until cops or reinforcements arrived. That was a silly day.
Shooters tend to be mentally ill people who have been pushed too far by a system, trying to burn that system down.
Killing a boss with a keycard that opens everything might not just be possible but also preferable. Fuck you Tom, you made me work through memaw’s funeral
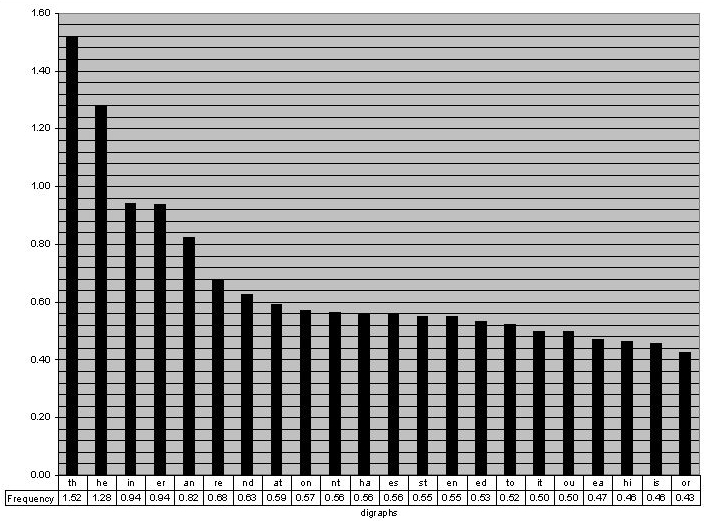
Looking at the English keyboard and the English digraphs, it doesn't seem like the coverage is that well optimized. We are currently capturing 8.65% of the digraph weight, but just getting the top-5 would account for 5% by itself.
I also feel like distance travelled is the wrong (or an incomplete) metric. Change in direction seems like a good proxy for mental or physical effort. To take it to an extreme, I'd be very satisfied with a keyboard that had me move my thumb in a circle as on the original iPod, provided it just read my mind and inputted the right text. That's extreme distance but little effort.
+---------+---------------+-----------+-------------------------------------+
| Digraph | Frequency (%) | Adjacent? | Pair on Keyboard |
+---------+---------------+-----------+-------------------------------------+
| TH | 1.52 | Yes | T is right of H |
| HE | 1.28 | No | Separated by O and [Space] |
| IN | 0.94 | Yes | I is top-left of N |
| ER | 0.94 | Yes | E is below R |
| AN | 0.82 | No | A is bottom-center; N is top-right |
| RE | 0.68 | Yes | R is above E |
| ND | 0.63 | No | N is top-right; D is bottom-right |
| AT | 0.59 | No | Separated by [Space] and S |
| ON | 0.57 | No | Separated by H and T |
| NT | 0.56 | Yes | N is top-right of T |
| HA | 0.56 | No | Separated by [Space] |
| ES | 0.56 | No | Separated by [Space] |
| ST | 0.55 | Yes | S is below T |
| EN | 0.55 | No | N/E are on opposite sides |
| ED | 0.53 | No | E is center-left; D is bottom-right |
| TO | 0.52 | No | Separated by H |
| IT | 0.50 | Yes | I is above T |
| OU | 0.50 | Yes | O is below U |
| EA | 0.47 | Yes | E is top-left of A |
| HI | 0.46 | Yes | H is below-left of I |
| IS | 0.46 | No | Separated by T |
| OR | 0.43 | Yes | O is below R |
| TI | 0.34 | Yes | T is below I |
| AS | 0.33 | Yes | A is below-left of S |
| TE | 0.27 | No | Separated by H and [Space] |
| ET | 0.19 | No | Separated by H and [Space] |
| NG | 0.18 | Yes | N is above G |
| OF | 0.16 | Yes | O is below F |
| AL | 0.09 | Yes | A is right of L |
| DE | 0.09 | No | E/D are distant |
+---------+---------------+-----------+-------------------------------------+
I agree that distance is not a great metric. The maximum travel distance on a smartphone screen is already tiny. I'd say the best metric is accuracy or lack of amibiguity, something like average confidence level that any given swipe means a particular word and not another. (This is assuming swipe-based word entry, which I much prefer to anything tap-based.)
> distance travelled is the wrong (or an incomplete) metric.
Indeed, most of these keyboard algorithms use only plausible useful metrics and only plausible real text (like, how many designs account for the fact that you make typos and need to correct them, is backspace location accounted for? What about symbols?)
We already have effectively write-only code. It's all the assembly language and eventually machine code that we produce from other languages.
The problem with "write-only code" as it relates to LLMs is that we don't have a formal definition of the input the the LLM, nor do people typically save the requirements, both implicit and explicit, that were given the LLM to generate the code. English language will never be a formal definition, of course, but that obviously doesn't prevent the creation of a formal definition from English nor reduce the value of the informal description.
This is very similar to the problem of documentation in software development. It is difficult to enumerate all the requirements, remember all the edge cases, recall why a certain thing was done in a certain way. So computer programs are almost never well documented.
If you knew that you currently have a bunch of junior developers, and next year you will replace all of them with senior developers who could rewrite everything the junior developers did, but taking only a day, how would that affect your strategy documenting the development work and customer/technical requirements? Because that's what you have with current LLMs and coding agents. They are currently the worst that they'll ever be.
So there are two compelling strategies:
1) business as usual, i.e. not documenting things rigorously, and planning to hack in whatever new features or bugfixes you need until that becomes unsustainable and you reboot the project.
2) trying to use the LLM to produce as much and as thorough documentation and tests as possible, such that you have a basis to rewrite the project from scratch. This won't be a cheap operation at first, (you will usually do strategy #1), but eventually the LLMs and the tooling around managing them will improve such that a large rewrite or rearchitecture costs <$10k and a weekend of passive time.
Is that really true though? Are people really not saving design documentation to the code repository along with the code? And is it really too much to ask in a prompt to make the LLM document aggressively? Do the LLMs you use complain about being asked to write lots of comments in their code? Is it a token cost thing? It seems ridiculous not to just start with #2 but I might be spoiled by not knowing how much my token usage costs.
It requires real work to create good documentation and review it.
I've never worked in a place that requires that every commit update some documentation, but if you want to rebuild software based on the documentation, that's what it would take.
The best you could say is that the typical development process today tends to scatter documentation across commit descriptions, feature docs, design reviews, meeting notes, training materials, and source code comments.
To have a hands-off rewrite of a codebase with LLMS, you would need a level of documentation that allows a skilled human to do the rewrite without needing to talk to anyone else. I doubt that any project would have this unless it was required all along.
It doesn’t though. You tell the LLM what to document up front, it can be some domain specific detail or whatever. You don’t need to carefully review it unless things go wrong. You do change propagation and change everything (tears, docs, code) in sync when some spec aspect changes, which involves a QA feedback loop, which judges the correctness of code and tests (because the LLM wrote the tests, they can be wrong). I guess you could add doc review steps as well if you knew what to look for generically, but I found it’s ok at writing docs that I haven’t needed to do this yet.
The only docs that explain what code does are a carbon copy of the code.
I've saw that "no-code, write docs, write spec" movie so many times, and it always ends as a flop in the box office.
It will never work. Code is the documentation.
The difference between Code -> IR -> binary is that the transition is deterministic.
Doc -> Code is non-deterministic asf. And will never be.
The only reason it works and we have senior, middle, junior engineers is the fact that assumptions on that path that senior engineers make are better than the ones junior engineers make.
LLMs cannot make any assumptions though, as they have zero real world knowledge and thus zero common sense.
I think there's some truth to this. Toyota desperately needs the future to play to their strengths, something more complicated than EVs, which I think is behind their obsession with hybrids.
Not sure that a fuel cell vehicle isn't just an EV with extra steps, however.
Goldtouch Elite is the gateway drug. It offers both a hinged split and tenting if you want it, while having the classic keyboard layout. Microsoft natural also requires very little learning curve, assuming that you don't use the wrong hand for some of the middle keys out of habit.
I use Kinesis Advantage2. I suppose they should be relatively cheap on eBay now. They still have a slight amount of ulnar deviation, but I find it's the best keyboard I've ever owned. I don't use all the macros and foot pedals and whatnot. You don't lose the ability to touch type on a standard keyboard, and it really only takes a day or two to have some proficiency, and maybe 2 weeks to get to full speed on the Kinesis. It helps greatly that all the letter keys are the same; it's just the thumb keys and the arrow keys that take some getting used to.
One massive advantage of the old Advantage2 is that there's a big empty space in the middle (with just the indicator lights). You can use museum wax to stick an Apple trackpad there, and then you hardly move your hands at all. I still have a trackball for large mouse movements or whatever, but most of the fine movements are done on the Apple trackpad at the center of the keyboard.
The size of encrypted data is completely independent of the block size of a block cipher function that is used for data encryption.
Nowadays, there is almost never any reason to use for encryption any other modes of operation except CTR or OCB, which do not expand the size of encrypted data.
That said, the parent article was less about encryption and more about random number generation, which is done by encrypting a counter value, but you never need to decrypt it again.
In RNGs, the block size again does not matter, as the output can be truncated to any desired size.
The problem domain is that you want to separately encrypt/decrypt various 32-bit serial numbers.
CTR mode turns this into just an XOR operation. That provides very little security. Anyone observing sequential sequence numbers (particularly rollovers) will quickly derive the partial value of the first CTR mode cipher block.
A 32-bit cipher, on the other hand, essentially creates a permutation of the entire 32-bit space that's reversible with the key. Ideally, the encrypted value of serial #1 tells you nothing about the value of serial #2, which is the case for practical 32-bit ciphers.
AES is most often used in a streaming mode, where it's used to generate a keystream. AES alone is useless, it MUST have a mode of operation to provide any security. A streaming mode can then encrypt any number of bits greater than 0. AES-CTR is one of the more common streaming modes.
Depositors are lending their money to the bank at low interest. They may seek risk in terms of increased yield on their savings account, but FDIC insured banks will have trouble meeting their requirements while offering high yields on their accounts.
Banks provide security for deposits as well as liquidity (velocity of money), and slight inflationary pressure.
Wiping out depositors doesn't prevent much moral hazard since the depositors are unsophisticated, so they are unable to differentiate risk among banks.
Unsophisticated depositors are not holding more than $250k of cash in bank accounts. The problem is not that depositors were made whole, the problem is that the FDIC insurance prices are based on limited losses, when for all intents and purposes, the depositors' risk is completely based on their political influence.
This type of corruption is antithetical to a strict, rules based system, which is needed for trust in the financial system. Either give everyone the same protection explicitly, or follow the rules.
Also, the rules and lack of centralization might have made sense when cash was a thing, but in a society where electronic money is the primary mode of payment, I see no reason why a non government entity should be involved at all in the simple act of maintaining a record of how much money is an account and adding and subtracting to it.
{kind=link}
> We better remove and halt nuclear powers for the rest of my life.
Neither of those things is a guaranteed outcome of this. Depending on who you ask, it's not even a likely outcome.
The IRGC remains the most powerful group in Iran. Probably a military junta is a more likely outcome, plus or minus a civil war to establish it.
reply