When you're the paying customer, it's possible (but not guaranteed) that they could see privacy as product differentiation.
In other words, if company A and B both offer you a product for $N, but A protects your privacy better than B, then A might get more customers. This competitive advantage can be an incentive for privacy.
However, there definitely limitations. If the value of this competitive advantage is less than the revenue they make by selling your data, then it's not a strong enough incentive. It also only works if consumers care about privacy and take the time to factor it into their purchasing decision.
I think the safety officer meant that white paint prevents the rail from heating up. The heating of rails contributes to problems with derailment. If the heat isn't a contributor, that heat is one less thing you have to fight (as in account for).
But the photo caption paraphrases him and says that the white paint fights (as in prevents) the heat, which uses similar words but a different logic to it (but the same overall meaning).
If I've got that right, then I think the blame lies on whoever wrote this article for making it confusing.
It's pretty easy on Linux with the compose key. To get "≠", you just hit compose, then "/", then "=". That's actually the same number of keystrokes as "!=" (since "!" requires the shift key).
For whatever reason, the OS documentation lacks a list of allowed compose key sequences. But they are intuitive enough that you can find many of them through experimentation. For example:
I mean I don't think it's unfair to say that most of the battle-tested encryption is "uncrackable enough" for the consumer.
If you're working for the NSA you need to worry about these things being cracked, obviously, but for the "I don't want a scammer to buy my laptop and get my social security number" situation, I think that you really can just assume that LUKS is uncrackable.
That said, it takes like five minutes to boot a live Linux flash drive and run fdisk to delete the partitions and/or install Mint or something over the existing data, so I don't really see any reason not to do it, even if it's not strictly necessary.
Companies generally fail because either their product doesn't meet a market need, or the market doesn't exist in the first place (possible because of bad timing), and not because they simply outran their competitors.
These aren't things fixed by using a frontier model to vibe code faster in lieu of one 5 months behind.
Making better software than my competitors and keeping my business afloat is my goal. I use whatever better tool gives me the edge.
I focus on doing better work for the most part. But there is also stuff I do now, because the SOTA models can handle it, that I would otherwise just wouldn't do.
Not sure about OP, I usually make Opus 4.8 on Extra thinking level implement features for me on a specific project, while I'm busy with other stuff.
For a change, I let DeepSeek V4 Pro implement it on Max thinking level. Nothing too out there - some DB migrations, some Django back end changes and Vue SPA front end changes.
Implementation time in total including tests was a few hours, so nothing too egregious. However, one of the migrations would break with pre-existing data, one of the column references in the entity was wrong, the API endpoint wasn't made consistently with the others in adjacent code (e.g. permission checks) and the front end had a Pinia state related issue and submitting one of the forms didn't work.
Tooling was run: ruff, ty, Oxfmt, Oxlint, also Docker build was green across the board, but the overall feature just didn't work. In both cases, sub-agents with clear context would review the code for serious/critical issues, at least three in parallel and do review loops until they spot nothing. The harnesses both has LSP integration.
Opus spent another hour fixing it, needed a few iterations, because I couldn't be bothered there.
> What's your competitive edge here? Shaving off an hour of a feature delivery? Not having to see the code that is produced?
The difference largely was not needing to waste time in fixing all sorts of subtle bugs that sub-optimal models will produce, worse yet if it was some sort of a serious project and those wouldn't have been spotted but instead that slop would have gotten shipped.
That said, Opus isn't ideal either and messed up a whole bunch when I was training some neural nets and try to process a bunch of satellite data and configure Garage to store them so that tiles can be served from a slow HDD and stuff like that. Obviously, it also needs a lot of babysitting in regards to UI looks, but it's better at the rest of development.
I think that DeepSeek V4 Pro and GLM 5.2 are cool though, it's just that you want as many checks and tests as you can throw at any given problem, or use languages that make shipping completely broken code increasingly likely.
A bank card is a type of card. Credit cards and debit cards are both bank cards. Prepaid cards are another type.
With any type of bank card, there's a bank that guarantees to a merchant that they will later receive a payment. With a debit card, the guarantee is backed by money you have on deposit. With a credit card, it's backed by the bank's money, which is higher risk for the bank.
Two US companies, VISA and Mastercard, have big networks for processing transactions with bank cards. These networks act as intermediaries to connect merchants (who want to accept payments) and banks (who issue cards) together. It's much simpler for a merchant to send a request to (say) VISA than to figure out which bank issued each customer's card. The payment networks also define, publish, and enforce standards and rules for the payment process.
These networks aren't banks. But they are, in a sense, bank card companies because they are part of the bank card system.
So in other words, European consumers have an account at a European bank that issues them a card they can use for purchases at European businesses, but US networks connect it all together.
This says the main reason for four-tube is image registration. Basically, the incoming light is optically split up into red, green, and blue, and these go to separate sensors. Being separate sensors, they may not be physically aligned. So if you sum R + G + B together to get luminance, the picture will not be sharp.
You can solve this by adding a fourth (black and white) tube for luminance. Since it's just one tube, there is no alignment issue for the luminance part of the picture. And the eye is less sensitive to color, so while the color alignment issues remain, they aren't very noticeable.
At first when I read this, I assume the camera must have to somehow combine the fourth tube's signal with the other three tubes' signals. But since both NTSC and PAL encode luminance and chrominance separately, apparently this isn't necessary. It's the TV that combines them. With a three-tube camera, the sensor signals have to be split into luminance and chrominance. With a four-tube camera, you just take luminance from one sensor and chrominance from the other three sensors.
Seems like if Lore wants to reduce space usage, they could apply something like Git's delta compression (as used in packfiles) to the chunks.
Suppose you make a 1 kB change in a 50 MB file. That causes a 64 kB chunk to be created and stored. Disk space is wasted.
But since the 50 MB file was already stored as a sequence of 64 kB chunks, there is an existing 64 kB chunk that is very similar to your new 64 kB chunk. You can store your new chunk as a delta to that, so only ~1 kB of disk space is used.
Admittedly, it's complicated and inelegant. But it allows both deduplication between files (one of the reasons Lore chose chunks, apparently) and efficient space usage for small changes.
> Three decades later, with the release of macOS 26.5, Apple caught up: you can finally set your Mac to 'Always' boot whenever power is restored, regardless of how it was shut down.
Back in the 1990s, a Mac sysadmin showed me a clever trick for this.
Get one specific Apple Desktop Bus keyboard that has a soft power key on it, I believe the Apple Extended Keyboard[1]. Then get a Bic pen[2]. Push down the power key on the keyboard, and while it's still down, wedge the pen cap between the key and the keyboard case.
The pen cap is the perfect size and shape to hold the key down, and Bic pens are easy to find. There are no ill effects from having the power key down all the time, and the Mac will boot up after a power failure. So you don't have to drive to work just to push the power button.
This was especially handy considering you sometimes needed to use Macs as servers (file server, printing, certain Mac-only applications, etc.), but Apple did not make servers.
This was a neat hack in many of the early Macs between the 'big switch' ones (like the Mac Plus and SE) and the 'pushbutton' ones (like the Performas and Quadras).
You could even do it with your fingernail; just push in and twist the power button, and it would stay in forever, and the Mac would automatically boot when you plug it in.
Oh man that's nice. When I was in high school slugging along with a Mac LC, I dreamt of having the amazing Quadra 700 with its superior speed and graphics. Crazy that the price was $5,700 ($14K in 2026) and you just picked it out of the trash.
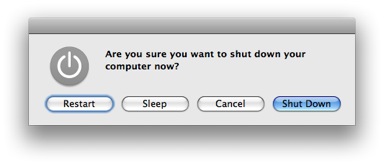
My memory from classic Mac OS is that pushing the keyboard soft-power key brought up a system-modal dialog asking if you wanted to shut down, restart, or cancel, a dialog with exactly the same design as: <http://www.christianboyce.com/page25/files/tipofthedayjulyth...>
That would obviously not be compatible with a server, maybe if soft power was just constantly held down starting from boot that dialog wouldn't show up?
{kind=link}
{kind=link}
{kind=link}
In other words, if company A and B both offer you a product for $N, but A protects your privacy better than B, then A might get more customers. This competitive advantage can be an incentive for privacy.
However, there definitely limitations. If the value of this competitive advantage is less than the revenue they make by selling your data, then it's not a strong enough incentive. It also only works if consumers care about privacy and take the time to factor it into their purchasing decision.
reply